[AWS] 데이터를 S3 버킷으로 백업 .
데이터를 S3 버킷으로 백업
1) S3 생성
AWS에 로그인 하여 S3버킷을 새로 생성합니다,

2-1) AWS CLI 사용을 위한 설정
중요 데이터는 오프사이트에 보관하는것이 안전하기 때문에 S3에 데이터 백업을 주로 하기 때문에 실습을 진행합니다 .
스크립트로 S3에 백업하려면 아마존의 AWS CLI 를 사용해야 합니다 .
이 명령줄 인터페이스는 파이썬에서 실행됨으로 컴퓨터에 파이썬을 먼저 설치 합니다 .
#yum -y install python3-pip
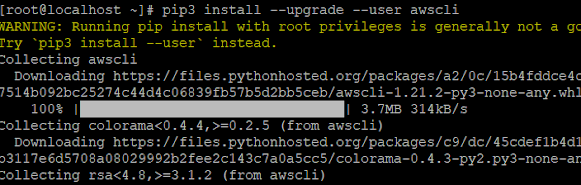
#pip3 install --upgrade --user awscli

2-2) AWS CLI 사용을 위한 설정
추가로
# curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
명령어를 통해 aws cli 프로그램을 다운받습니다 .
# unzip awscliv2.zip
3) AWS CLI와 연결
AWS 보안자격 증명을 클릭합니다 .
보안자격 증명의 액세스 키 ID를 생성하고 저장합니다 .
터미널에서 aws configure 명령어를 입력하고 엑세스키 ID 및 패스워드를 입력합니다 .


4) 자격 증명 입력
리눅스로 돌아와 aws configure 명령어를 입력하고 엑세스키 ID 및 패스워드를 입력합니다.

5) s3 확인
aws s3 ls | grep [생성한 버킷이름] 를 입력하면 생성한 S3이 나옵니다 .

6) S3 동기화
목표 :시스템에서 중요한 파일을 AWS S3에 자동으로 백업 .
적용기술 : AWS S3, crontab,
7) crontab설정
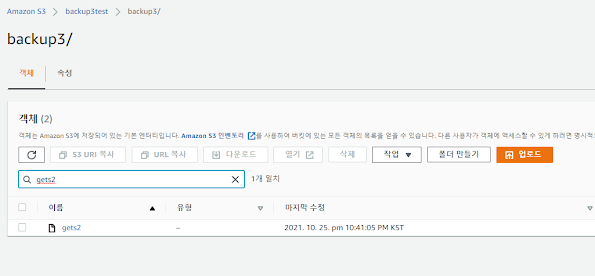
10월 25일 10시 41분에 /home/usera/dirbackup/gets2 를 S3와 동기화 한다 .


8) 동기화 확인
시간이 되면 다음과 같이 /var/spool/mail/root에 알림이 도착 합니다 ./ 로그 확인 (실패한 내역까지 잘 나와있습니다 .)
S3 버킷을 열어서 gets2 가 잘 업로드 되었는지 확인합니다 .